余弦相似度计算公式:python代码找出相似文章
用TF-IDF算法可以自动提取关键词。除了找到关键词,怎么找到与原文章相似的其他文章。比如,"百科TA说"在词条最下方,还提供多条相似的文章。
为了找出相似的文章,需要用到"余弦相似度"(cosine similiarity)。什么是"余弦相似度" ?
余弦相似度百度百科:余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。
为了简单起见,我们先从句子着手。
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
请问怎样才能计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
我,喜欢,看,电视,电影,不,也。
计算词频:
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
写出词频向量:
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
计算这两个向量的相似程度。余弦值越大,证明夹角越小,两个向量越相似。
我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
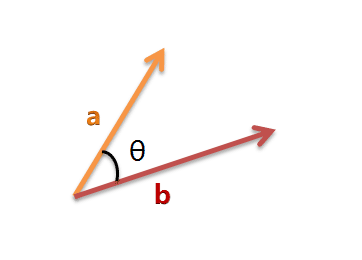
以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ。余弦定理告诉我们,可以用下面的公式求得:
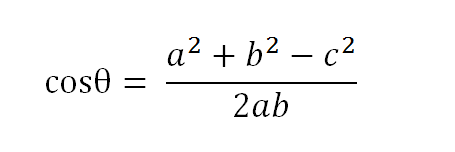
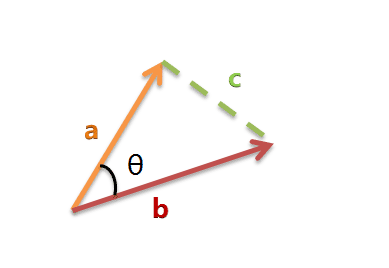
假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:
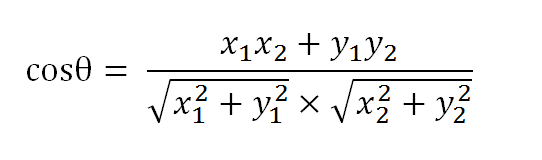
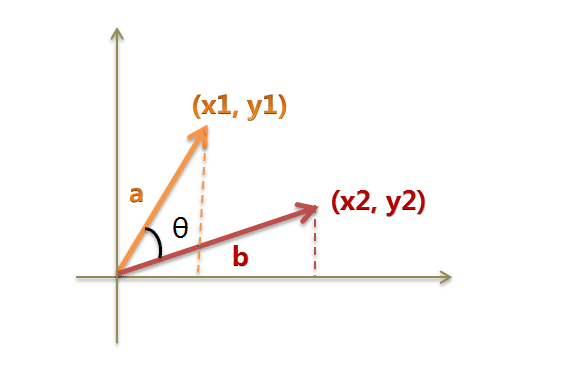
数学家已经证明,余弦的这种计算方法对n维向量也成立。假定A和B是两个n维向量,A是 [A1, A2, ..., An] ,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦等于:
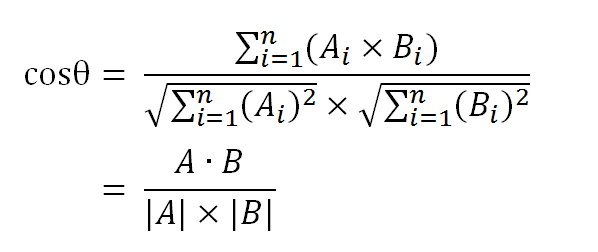
使用这个公式,我们就可以得到,句子A与句子B的夹角的余弦。
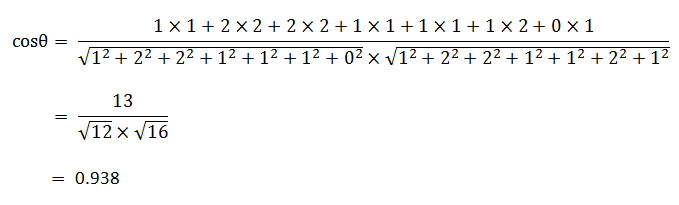
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。所以,上面的句子A和句子B是很相似的,事实上它们的夹角大约为20.3度。
由此,我们就得到了"找出相似文章"的一种算法:
(1)使用TF-IDF算法,找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
"余弦相似度"是一种非常有用的算法,只要是计算两个向量的相似程度,都可以采用它。
import jieba
import jieba.analyse
def words2vec(words1=None, words2=None):
v1 = []
v2 = []
tag1 = jieba.analyse.extract_tags(words1, withWeight=True)
tag2 = jieba.analyse.extract_tags(words2, withWeight=True)
tag_dict1 = {i[0]: i[1] for i in tag1}
tag_dict2 = {i[0]: i[1] for i in tag2}
merged_tag = set(tag_dict1.keys()) | set(tag_dict2.keys())
for i in merged_tag:
if i in tag_dict1:
v1.append(tag_dict1[i])
else:
v1.append(0)
if i in tag_dict2:
v2.append(tag_dict2[i])
else:
v2.append(0)
return v1, v2
def cosine_similarity(vector1, vector2):
dot_product = 0.0
normA = 0.0
normB = 0.0
for a, b in zip(vector1, vector2):
dot_product += a * b
normA += a ** 2
normB += b ** 2
if normA == 0.0 or normB == 0.0:
return 0
else:
return round(dot_product / ((normA**0.5)*(normB**0.5)) * 100, 2)
def cosine(str1, str2):
vec1, vec2 = words2vec(str1, str2)
return cosine_similarity(vec1, vec2)
print(cosine('宋建sem', '宋建sem'))
seo应用:文章原创度检测工具
下一次,我想谈谈如何在词频统计的基础上,自动生成一篇文章的摘要。

本文地址:https://www.360baidu.cn/seo/cosine.html
宋建微信
关注公众号
免费领取 机械运营 全网营销方案
© 2019 宋建 www.360baidu.cn All Rights Reserved.

汽车违章查询系统
2019-12-21 上午 11:57